Cracking the Code: Scaling Model Inference & Real-Time Embedding Search



 By mid-2023, we had transformed our ML stack—building a real-time feature store, optimizing model retrieval, and fine-tuning ranking. But two critical gaps remained:
By mid-2023, we had transformed our ML stack—building a real-time feature store, optimizing model retrieval, and fine-tuning ranking. But two critical gaps remained:
- 🔹 Scaling model inference without hitting infrastructure roadblocks
- 🔹 Moving embedding search from batch to real-time for candidate generation
Here’s how we tackled these last-mile challenges, broke free from infrastructure constraints, and built a cost-efficient, high-performance system.
Breaking Free from the Scalability Ceiling
The Model Serving Bottleneck—A Wake-Up Call
July 2023. With just months left for the Mega Blockbuster Sale (MBS), we noticed a serious issue—scaling our model-serving infrastructure was taking 10–15 minutes. In real-time ML, that’s an eternity. In one of our war rooms, we ran a quick experiment:
- 🚀 We deployed an XGBoost model on a self-hosted Triton Inference Server running on a 16-core machine.
- 🚀 Fired requests and compared the outputs with our existing cloud-hosted setup.
- 🚀 The results matched—perfectly.
That moment changed everything. We prepped a backup Triton setup on EKS, just in case our cloud provider couldn't allocate enough compute resources in time. Luckily, they did—but the seed was planted. Then in October, just two weeks before MBS, we got an alarming response from our infrastructure team: "Node availability may be an issue." With no time to waste, we moved 30% of real-time ML traffic to our self-hosted Triton cluster. The results?
- ✅ p99 latency dropped from 90–100ms to 30–40ms
- ✅ Triton handled significantly higher throughput on fewer resources
- ✅ No model changes were needed
MBS ran without a hitch, proving that self-hosted inference was the way forward.
Scaling Triton on GKE
This left us with two choices:
- 1️⃣ Port models to a managed cloud inference service, investing time in learning a new deployment stack
- 2️⃣ Scale our existing Triton setup on GKE, optimizing for cost and performance
We went with Option 2—and it slashed inference costs to 35% of what we previously paid, while giving us full control over scaling and optimizations.
Fixing the Cold Start Problem
As we onboarded more deep learning (DL) models, we hit a new bottleneck, new inference pods took 7–9 minutes to spin up.
After profiling, we found the culprits:
- Triton’s base image—a massive 5GB
- Model binaries—often 1GB+
- Startup delay—mostly due to downloading and initializing these assets
To fix this, we built a lightweight Triton image, stripping unused components and shrinking the size to 900MB. This cut cold start times drastically, making auto-scaling faster and smoother.
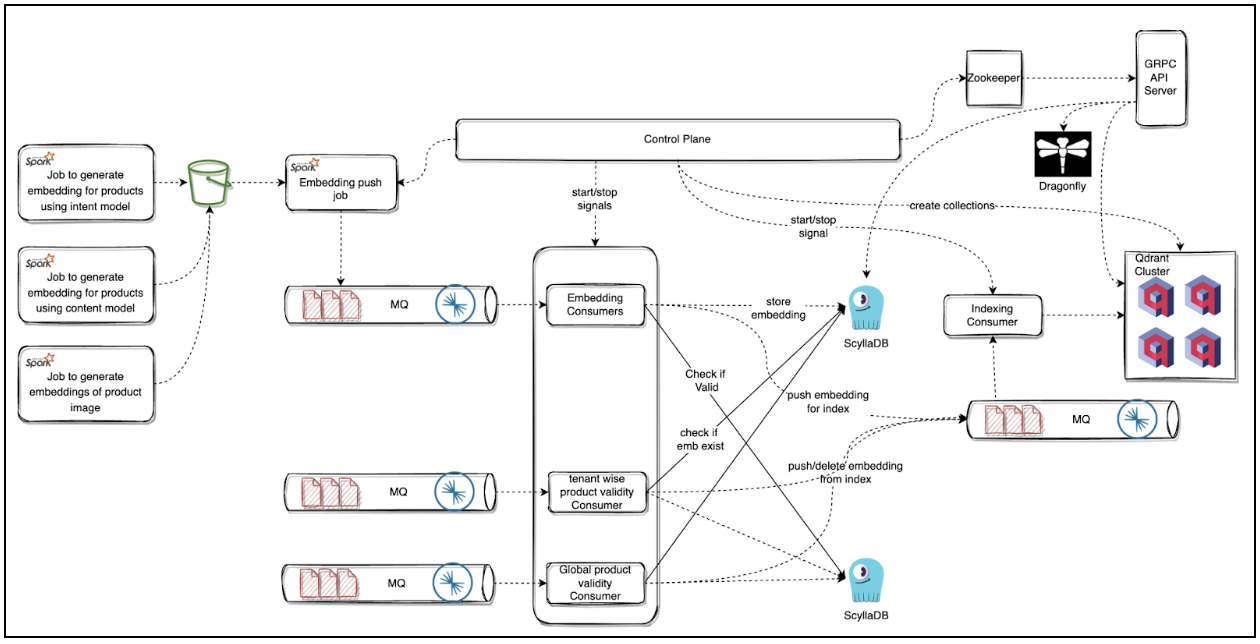
Embedding Search: The Last Piece of the Puzzle
By mid-2023, most of our ML stack had gone real-time—except for Candidate Generation (CG), which still ran in batch mode. To truly power real-time recommendations, we needed an online embedding search system.
Choosing the Right Vector Database
We benchmarked three production-ready vector DBs across key parameters:
- Milvus
- Qdrant
- Weaviate
After extensive POCs, Qdrant stood out for its:
- ✅ Blazing-fast search latency on high-dimensional vectors
- ✅ Efficient memory usage, crucial for in-memory workloads
- ✅ Support for upserts and soft deletes, vital for Ads use cases
- ✅ gRPC + REST APIs, making integration seamless
- ✅ Powerful filtering, allowing fine-tuned retrieval (e.g., filtering Ads by category, active status, etc.)
At its core, Qdrant uses HNSW indexing, delivering both high recall and low-latency nearest-neighbor search—a perfect fit for our needs.
Embedding Freshness & Real-Time Updates
To ensure embeddings stayed up to date, we built a dual ingestion pipeline:
- 📌 Daily Refresh: A bulk pipeline updated embeddings overnight
- 📌 Real-Time Updates: Ads events triggered immediate upserts/deletes
This setup powered real-time "Similar Products" recommendations on the product page and became the foundation for Ads Candidate Generation, ensuring the right ads surfaced in milliseconds.
Final Takeaways: Scaling Smartly for Real-Time ML
- 🚀 Self-hosted inference on Triton gave us lower cost, faster scaling, and better performance than managed services
- 🚀 Building a custom Triton image reduced cold starts, improving responsiveness
- 🚀 Qdrant-based embedding search enabled real-time personalization at scale
- 🚀 Real-time updates for embeddings unlocked dynamic, up-to-date recommendations
By early 2024, Meesho’s ML stack had evolved into a fully real-time, scalable, and cost-efficient system, setting the foundation for even bigger leaps ahead.