Building Meesho’s ML Platform: Lessons from the First-Gen System (Part 2)



 By late 2022, we had built something we were truly proud of—a real-time ML serving system with a DAG-based executor, a feature store, and an interaction store powering key ranking and personalization models. It was a major milestone, the culmination of months of effort from data scientists, ML engineers, and backend teams. Our system was live, and we were ready to push the boundaries of experimentation.
And it worked. Mostly.
But soon, cracks appeared. Every new model needed custom feature retrieval logic, DAGs became dense and unmanageable, and scaling turned into a constant firefight. Costs surged, and infra bottlenecks slowed experimentation. Our system worked, but it wasn’t built for scale.
This is the story of how we tackled these challenges—building Inferflow for seamless feature retrieval, optimizing real-time infra, and cutting costs while scaling to millions of QPS.
By late 2022, we had built something we were truly proud of—a real-time ML serving system with a DAG-based executor, a feature store, and an interaction store powering key ranking and personalization models. It was a major milestone, the culmination of months of effort from data scientists, ML engineers, and backend teams. Our system was live, and we were ready to push the boundaries of experimentation.
And it worked. Mostly.
But soon, cracks appeared. Every new model needed custom feature retrieval logic, DAGs became dense and unmanageable, and scaling turned into a constant firefight. Costs surged, and infra bottlenecks slowed experimentation. Our system worked, but it wasn’t built for scale.
This is the story of how we tackled these challenges—building Inferflow for seamless feature retrieval, optimizing real-time infra, and cutting costs while scaling to millions of QPS.
The Cost of Success
Every new Ranker model required its own feature set, often pulling from different entities. Each addition meant:
- Adding new DAG nodes in IOP
- Writing custom logic to fetch features from multiple sources (e.g., user, product, user × category)
- Inferring intermediate features (e.g., extracting category from a product to fetch user × category data)
- Optimizing I/O and dealing with the inevitable bugs
What began as clean DAGs soon turned into a tangled web of cross-dependent graphs. Every experimentation cycle meant new nodes, new dependencies, and slower iterations.
Scaling Pains (and Cassandra’s Limits)
At some point, we were hitting:
- 250–300K reads/sec
- 1M writes/sec (during lean hours)
All of this ran on Cassandra. While its distributed architecture had been proven in production, operating large-scale clusters came with considerable infrastructure overhead. Our proof-of-concept (POC) demonstrated throughput of around 100K ops/sec, but as we scaled further, the challenges grew. Ensuring node health, optimizing compaction, and maintaining storage balance became increasingly demanding. We also observed latency spikes under heavy load, alongside a sharp increase in total cost of ownership.
Interaction Store Woes
Our interaction store was another ticking time bomb:
- 🚨 Clusters kept growing in size and cost
- 🚨 Latency spikes became increasingly frequent
- 🚨 The DMC proxy occasionally lost locality of nodes against shards, causing cross-node communication and degraded performance
Each time this happened, we had to manually rebalance shards just to restore stable latency, making operations unsustainable at scale.
Silver Linings
Despite the chaos, the system was live and delivering value:
- Real-time infrastructure was in production
- Costs dropped by 60–70% compared to offline personalization
- New experiments rolled out faster and more successfully
- User engagement metrics improved
It wasn’t perfect. It was far from easy. But it worked—and that counted for a lot.
Round Two: Solving the Top 2 Bottlenecks
With the first-gen system stretched to its limits, we stepped back. Conversations with data scientists and backend engineers revealed three recurring pain points:
- Coding feature retrieval logic for every new model was becoming unsustainable
- ML scale was exploding—bringing rising infra costs with it
- Real-time embedding search was the next big unlock
We tackled them one by one—starting with the biggest pain point.
Problem 1: No-Code Feature Retrieval for Model Inference
We noticed a pattern: for personalized ranking, models needed features from:
- ✅ Product
- ✅ User
- ✅ User × Category
- ✅ Region, cohort, sub-category, etc.
A key insight emerged: Entities that contribute features for a model always map back to the context entities.
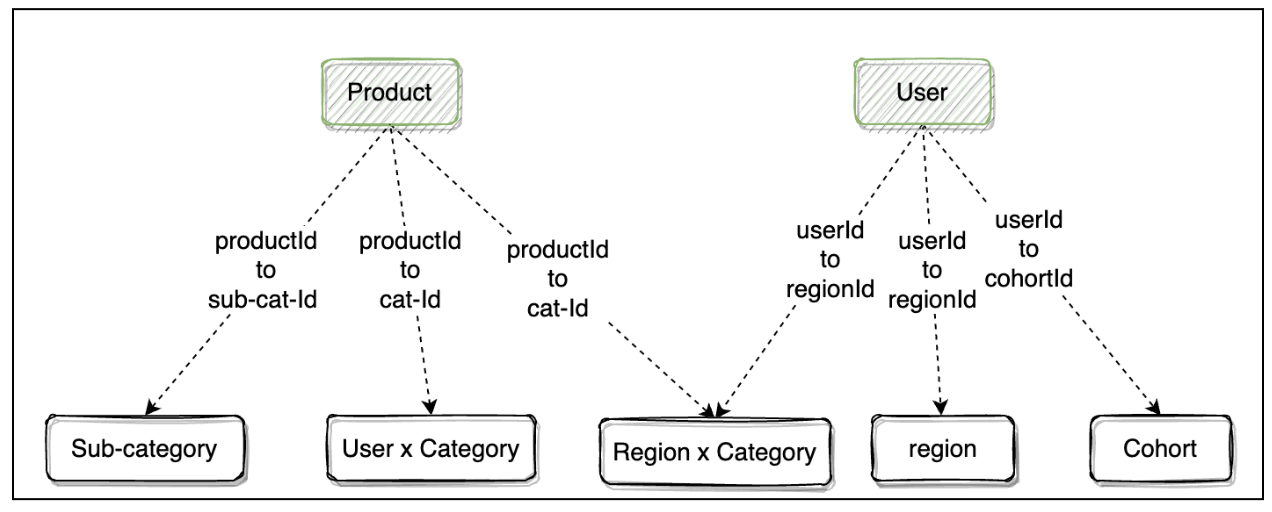
With this, we designed Inferflow, a graph-driven feature retrieval and model orchestration system:
- 1️⃣ Inferflow takes a modelId and context IDs (e.g., userId, productIds)
- 2️⃣ Loads a pre-defined feature retrieval graph from ZooKeeper
- 3️⃣ Executes the graph to resolve entity relationships dynamically
- 4️⃣ Outputs a 2D matrix of feature vectors
💡 The impact?
- 🚀 No more custom feature retrieval code—just graph updates in config
- 🚀 Feature consistency across experiments
- 🚀 Faster iteration cycles for ranking, fraud detection, and beyond
Here’s a visual example that shows how this graph plays out during execution. We further extended the graph to call multiple models as needed:
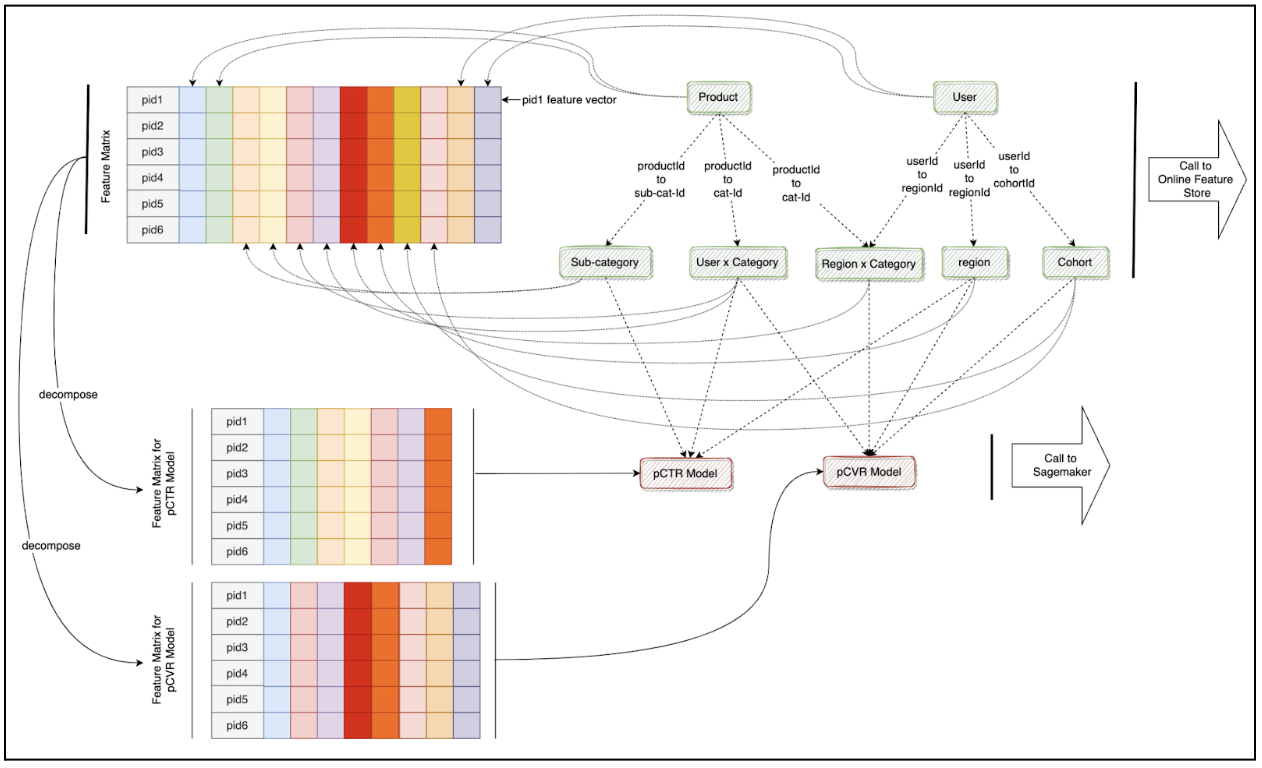 We built Inferflow in GoLang, using gRPC and Proto3 serialization for efficiency.
We built Inferflow in GoLang, using gRPC and Proto3 serialization for efficiency.
Problem 2: Scaling Without Breaking the Bank
With more ML use cases coming online, we needed to cut costs without compromising performance. We focused on:
- 🔹 Online Feature Store
- 🔹 Interaction Store
Optimizing the Online Feature Store
Our costs were concentrated in:
- 📌 Database (Cassandra)
- 📌 Cache (Redis)
- 📌 Running Pods (Java services)
1️⃣ Replacing Cassandra with ScyllaDB As we hit the operational limits of large Cassandra clusters, we transitioned to ScyllaDB, which offered a seamless drop-in replacement without major code changes. The switch brought significant benefits:
- Throughput: Matched or exceeded Cassandra's performance under identical workloads, even under high concurrency.
- Latency: Achieved consistently lower P99 latencies due to ScyllaDB's shard-per-core architecture and better I/O utilization.
- Cost Efficiency: Reduced infra footprint by ~70% through better CPU and memory efficiency, eliminating the need for over-provisioned nodes.
2️⃣ Finding the Right Cache To reduce backend load and improve response times, we benchmarked multiple caching solutions—Memcached, KeyDB, and Dragonfly—under real production traffic patterns. Dragonfly stood out due to its robust architecture and operational simplicity:
- Data Skew Handling: Efficiently managed extreme key hotness and uneven access patterns without performance degradation.
- Throughput: Delivered consistently high throughput, even with large object sizes and concurrent access.
- Ease of Adoption: Acted as a drop-in Redis replacement with full protocol compatibility—no changes needed in application code or client libraries.
3️⃣ Moving to GoLang for Cost-Efficient Serving Java services were memory-heavy—so we rewrote core services in GoLang. The results?
✅ Memory usage dropped by ~80% ✅ CPU utilization was significantly lower ✅ Faster, more efficient deployments
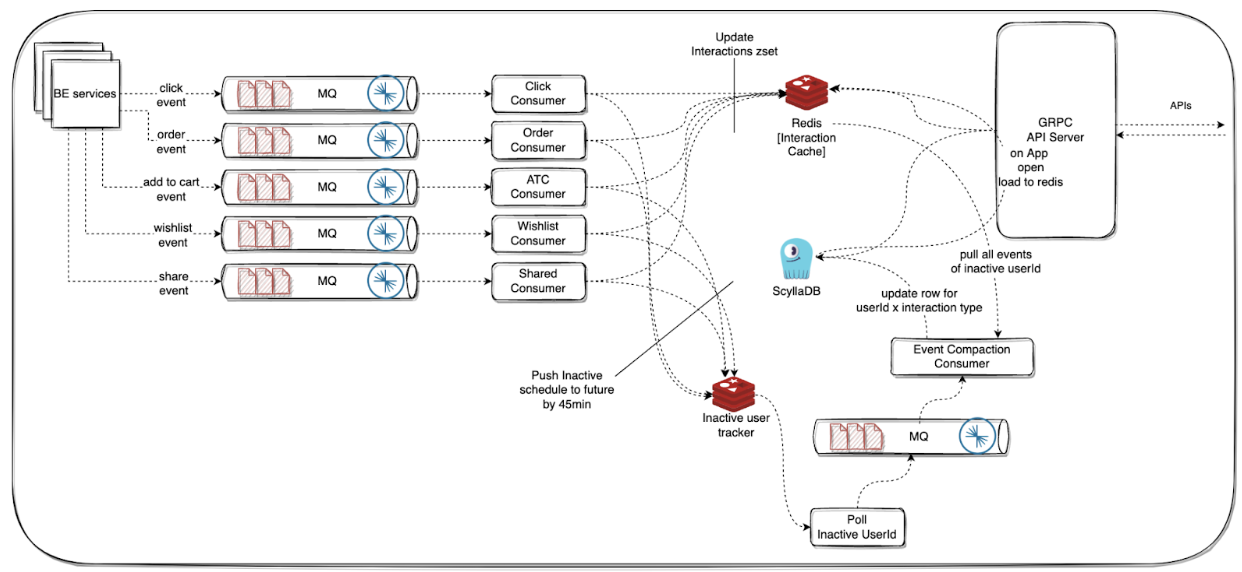
Optimizing the Interaction Store
We realized that we only need a user’s interaction data in Redis when they open the app. So, we implemented a tiered storage approach:
- 📌 Cold Tier (ScyllaDB)—Stores click, order, wishlist events
- 📌 Hot Tier (Redis)—Loads a user’s past interactions only when they open the app
Smart Offloading: We introduced an inactivity tracker to detect when a user session ends. At that point, Redis data was flushed back to Scylla, reducing unnecessary writes.
Results
- Online Feature Store hit 1M QPS for the first time during the 2023 Mega Blockbuster Sale—without breaking a sweat
- Infra costs for Online Feature Store and Interaction Store dropped by ~60%
The Catch: Our ML Hosting Hit a Hard Limit
While planning for 2023 MBS, we ran into a critical scalability bottleneck:
- ❌ Insufficient compute availability in our region for ML instances
- ❌ Couldn’t provision enough nodes to handle real-time inference at scale
This forced us to rethink where and how we hosted our models. The existing setup was great for prototyping—but it wasn’t built to handle the bursty, high-QPS demands of real-world production workloads.
Conclusion: From Firefighting to Future-Proofing
What started as an ambitious experiment turned into a real-time ML infrastructure that powered millions of requests per second. We battled scaling pains, rethought feature retrieval with Inferflow, and rebuilt our infra stack for efficiency—driving down costs while improving experimentation velocity. But new challenges emerged. Our infrastructure could now handle scale, but our ML model hosting setup hit a hard limit. With compute availability bottlenecks threatening real-time inference, we faced a critical decision: how do we make model serving as scalable and cost-efficient as the rest of our stack? That’s the next piece of the puzzle—and the story of Part 3.