Designing a Production-Grade LLM Inference Platform: From Model Weights to Scalable GPU Serving

 Serving large language models in production introduces new challenges across infrastructure, performance optimization, and operational lifecycle management. The LLM Inference Platform addresses these challenges by providing a unified system for deploying and managing open-source and fine-tuned LLMs at scale.
Serving large language models in production introduces new challenges across infrastructure, performance optimization, and operational lifecycle management. The LLM Inference Platform addresses these challenges by providing a unified system for deploying and managing open-source and fine-tuned LLMs at scale.
The platform implements a complete LLMOps lifecycle — from model registration and automated compilation to deployment, runtime optimization, and monitoring. Designed as a self-service environment, users can onboard models directly from open repositories such as Hugging Face or upload custom fine-tuned models, and deploy them using a single-click workflow with no manual infrastructure or configuration steps required.
In addition to fully automated deployment, the platform allows users to select and apply custom inference optimization techniques — such as quantization strategies, batching configurations, and runtime-specific performance enhancements — enabling teams to balance latency, throughput, and cost based on their use case. The goal is to reduce operational friction while enabling high-performance, production-grade LLM inference.
Why LLM Inference Is not just bigger ML model serving
Large language model (LLM) inference introduces a fundamentally different set of challenges compared to traditional machine learning inference. While classical ML models typically perform a single forward pass to produce a fixed prediction, LLMs operate as autoregressive systems, generating outputs token by token based on previously generated context. This difference dramatically changes how inference systems must be designed, optimized, and scaled.
Autoregressive Generation and Sequential Computation:
Unlike traditional models such as classifiers or recommenders — where inference cost is relatively constant — LLMs generate responses incrementally. Each new token depends on all previously generated tokens, making inference inherently sequential and dynamic. This means latency and compute requirements vary significantly depending on prompt length and output size, introducing complexity in scheduling and resource allocation. Because tokens cannot be generated fully in parallel during decoding, GPUs may become underutilized without specialized batching and scheduling strategies. This has led to the development of dedicated LLM inference engines optimized for token-level execution.
Prefill and Decode Phases:
LLM inference typically consists of two distinct stages:
- Prefill phase — the model processes the input prompt and builds internal representations. This stage is compute-heavy and highly parallelizable.
- Decode phase — the model generates tokens sequentially, predicting one token at a time using previously generated context.
The decode stage often becomes memory-bound rather than compute-bound, which creates new performance bottlenecks compared to traditional ML workloads.
Context Management and KV Caching:
Another fundamental difference lies in how LLMs maintain context. Transformer-based models rely on attention mechanisms that require access to past token representations. To avoid recomputing these representations repeatedly, inference engines use key-value (KV) caching, which stores intermediate activations from previous tokens. KV caching significantly improves performance by eliminating redundant computation, but it introduces new challenges:
- Memory consumption grows with sequence length and batch size
- GPU memory becomes a critical bottleneck
- Efficient memory management becomes essential for scaling concurrent requests
This tradeoff between compute efficiency and memory usage is unique to LLM inference workloads.
Dynamic and Irregular Workloads:
Traditional ML inference typically operates on fixed-size inputs with predictable latency. In contrast, LLM requests vary widely in prompt length, output length, and runtime behavior. As a result:
- Batch sizes must be dynamic rather than static
- Requests may enter and leave batches asynchronously
- Scheduling systems must continuously rebalance workloads to maximize GPU utilization
These characteristics require specialized serving architectures that differ significantly from standard ML serving pipelines.
Streaming and User Experience Constraints:
Another distinguishing factor is the expectation of real-time streaming responses. Instead of returning a single output, LLM systems often stream tokens to users as they are generated. Because of these differences — sequential generation, growing memory requirements, dynamic workloads, and streaming constraints — LLM inference cannot be treated as a simple extension of existing ML serving systems. Production platforms must incorporate specialized runtime engines, advanced optimization techniques, and observability tailored specifically to LLM workloads.
LLMOps: High-Level Architecture
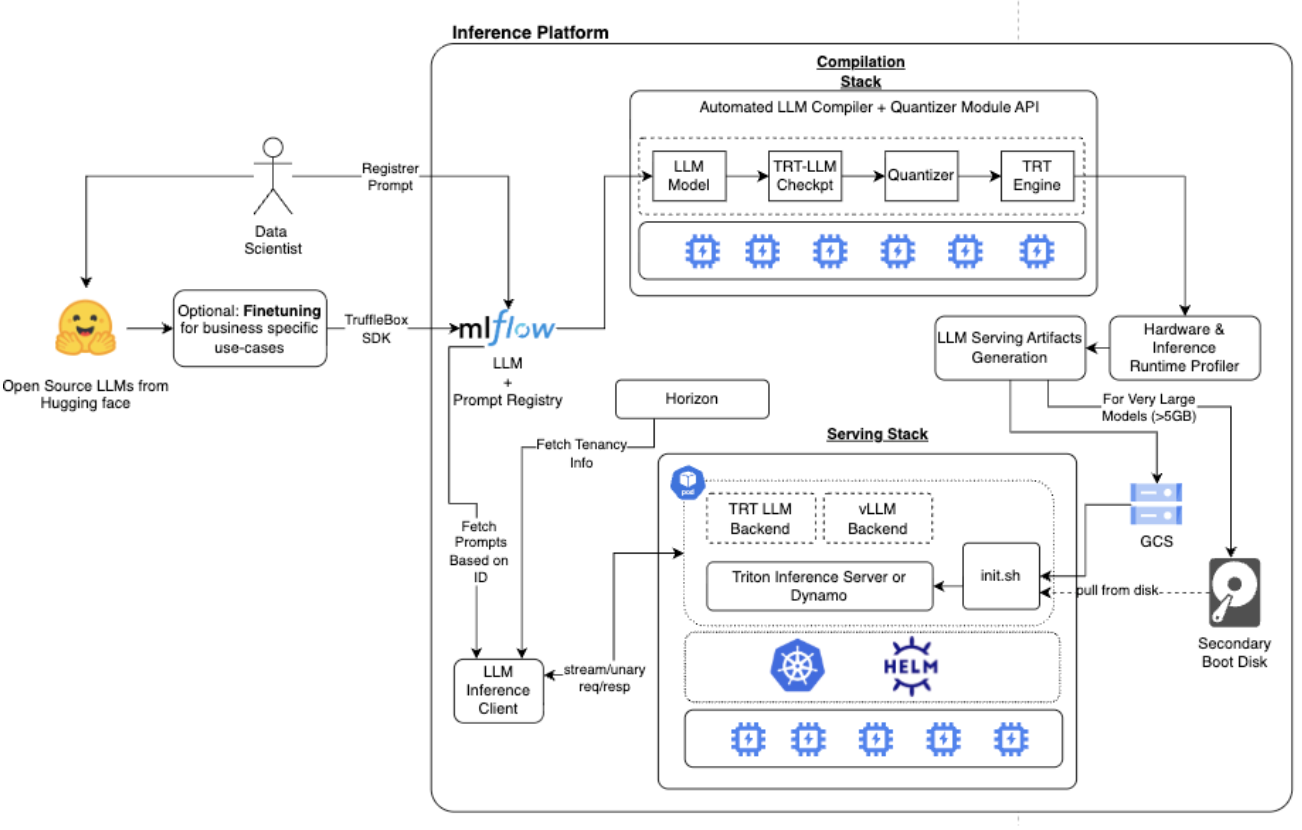
The LLM Inference Framework is designed as a fully automated, end-to-end system for deploying and operating open-source and fine-tuned large language models at scale. The architecture abstracts the complexity of model optimization, hardware selection, deployment, and runtime management into a unified workflow that enables users to move from raw model weights to production-ready inference endpoints with minimal manual intervention.
Our LLM Inference Framework is architected not just as a serving engine, but as a complete lifecycle management system. As illustrated in the high-level design below, the platform automates the journey of a model through seven distinct stages, ensuring reproducibility, performance, and scalability.
-
Onboarding & Registration (The Source of Truth)
The lifecycle begins with the Data Scientist or engineer.
- Model Ingestion: Users onboard models—whether open-source (Hugging Face, NeMo) or internally fine-tuned—via the Truffle Box SDK/UI.
- LLM + Prompt Registry: Unlike traditional systems that only track model weights, our registry is a unified control plane. It stores both the Model Artifacts and the Prompt Templates. This allows Data Scientists to register and version-control prompts (e.g., "customer_support_v2") independently of the application code.
-
The "Black Box" Build Engine
Once a model is registered, the Automated LLM Compiler + Quantizer Module kicks off a background job on ephemeral GPU resources.
- Transformation: The raw model is converted into a TRT-LLM Checkpoint.
- Quantization: The system automatically applies quantization algorithms (like INT4 AWQ or FP8) to reduce memory footprint.
- Engine Building: Finally, it compiles a highly optimized TRT Engine specifically tuned for the target hardware.
-
Intelligent Profiling & Validation
Before deployment, the new engine passes through the Hardware & Inference Runtime Profiler.
- Benchmarking: This module empirically tests the engine against various hardware configurations (L4 vs. A100) and runtimes (TRT-LLM vs. vLLM).
- Optimization: It recommends the optimal configuration that meets latency SLAs (Time-To-First-Token) while minimizing cost.
-
Smart Artifact Generation & Distribution
To solve the Kubernetes "Cold Start" problem, the LLM Serving Artifacts Generation module packages the model using a bifurcated strategy:
- Standard Models: Artifacts are uploaded to Cloud Storage (GCS) and downloaded by pods at startup.
- Very Large Models: For massive models (>8GB) where network downloads are too slow, the system pre-caches the model onto Secondary Boot Disks. These disks are attached directly to new GPU nodes during autoscaling, eliminating download wait times.
-
Image Streaming & Deployment
Simultaneously, the inference runtime container images are pulled from the Artifact Registry.
- Image Streaming: We utilize container image streaming to allow pods to start initializing while the massive Triton/Dynamo container layers are still downloading, further shaving seconds off the startup time. link
-
The Inference Runtime (Kubernetes)
The workload lands on Kubernetes with Autoscaling.
- Dynamic Backends: Depending on the profile generated in Stage 3, the pod initializes either TensorRT-LLM (for throughput) or vLLM (for flexibility), or spins up a Dynamo worker for distributed inference.
- Data Loading: The pod either downloads the model from Cloud Storage or mounts the pre-warmed Secondary Boot Disk ("Pull from Disk").
-
Client Interaction & Observability
Finally, the LLM Inference Client executes the request.
- Prompt Injection: The client pulls the specific prompt template ID from the Registry, ensuring the exact versioned instructions are used.
- Streaming Response: The request is sent via gRPC, and tokens are streamed back to the user in real-time.
-
Observability: Monitoring the Pulse of GenAI
In traditional microservices, success is measured by CPU utilization and request latency (p99). For Large Language Models, these metrics are insufficient. A user doesn't care if the GPU is at 80% utilization; they care about how fast the first word appears and how smoothly the rest of the sentence follows.
To capture the true user experience, our platform instrumentation focuses on three critical LLM-specific metrics:
-
Time to First Token (TTFT)
- Definition: TTFT measures the time elapsed from the moment a request is received until the very first token is generated and streamed back to the user.
- Why it matters: This represents the "Prefill Phase" latency—the time the model takes to process the input prompt and load weights. A high TTFT makes the application feel unresponsive or "hung."
- Optimization: We closely monitor TTFT to ensure our Prefix Caching is effective (aiming for high cache hitrates), which drastically lowers this metric by skipping redundant prompt processing.
-
Inter-Token Latency (ITL)
- Definition: ITL measures the average time interval between the generation of consecutive tokens during the "Decode Phase".
- Why it matters: This defines the "perceived speed" of reading. Even if the first token is fast (low TTFT), high ITL makes the text generation look "jerky" or slow to the user.
- Benchmarks: In our testing with Llama 3.1, we track p99 ITL to ensure it stays below human reading speeds to maintain a natural conversational flow.
-
Token Throughput vs. Request Throughput
- We distinguish between two types of throughput to balance system efficiency with user load:
- Token Throughput (tokens/sec): The total number of tokens generated across all concurrent requests. This measures the raw compute efficiency of the GPU and the effectiveness of batching.
- Request Throughput (req/sec): The number of distinct user queries served per second. We use this to determine autoscaling thresholds, ensuring we scale out before the queue depth impacts ITL.
-
The Monitoring Stack
- Real-time Dashboards: We utilize Grafana to visualize these streaming metrics in real-time, allowing on-call engineers to spot "slow generation" incidents that generic "500 error" alerts would miss.
- Request Tracing: Since Triton Inference Server does not log request payloads by default, we integrate a Helix Client to asynchronously publish request logs to Log Tables. This allows us to trace a specific "slow" request back to its prompt to understand if a complex input caused the latency spike.
-
Supported Inference backends (TensorRT LLM, Dynamo & vLLM)
Tailored for the Use Case: We do not believe in a "one-size-fits-all" approach to inference. Different use cases—whether a real-time voice bot requiring ultra-lowsub-second latency or a massive reasoning task requiring huge context windows—demand different runtime characteristics. Our platform is designed to be runtime-agnostic, allowing us to automatically select and tailor the best engine based on the specific requirements of the application:
-
TensorRT-LLM: The High-Performance Standard
Suitable for: High-throughput production workloads where latency is critical (e.g., customer support chat, real-time voice bots).
TensorRT-LLM serves as our default backend for these scenarios. Our internal benchmarks on Llama 3.1 and 3.2 models demonstrated that a tuned TensorRT-LLM engine significantly outperforms standard runtimes, especially when utilizing INT4 AWQ and FP8 quantization .
Key optimizations we tailor for these high-load cases include:
- Optimized execution via TensorRT engine compilation
- Quantization-aware execution for reduced memory usage and improved throughput
- Inflight Batching: Allowing requests to be processed continuously without waiting for the entire batch to finish, drastically improving GPU utilization .
- Custom Plugins: Enabling specific NVIDIA plugins like the GEMM plugin and GPT Attention plugin to accelerate matrix multiplications and attention mechanisms .
-
Dynamo: Distributed Inference for Reasoning Models
Suitable for: Very large "reasoning" models (70B+) or scenarios requiring massive context windows where a single GPU's memory is insufficient.
For these memory-bound tasks, we utilize Dynamo, a low-latency distributed inference framework . Unlike monolithic servers, Dynamo disaggregates the inference process to scale resources horizontally:
- KV Aware Routing: A specialized router directs requests to workers that already hold the relevant Key-Value (KV) cache, minimizing redundant computation .
- Prefill vs. Decode Split: The workload is divided into Prefill Workers (processing the prompt) and Decode Workers (generating tokens), allowing us to scale the compute-heavy "reading" phase independently from the memory-heavy "writing" phase .
- Distributed execution across multiple GPU resources
-
vLLM: The Flexible Baseline
Suitable for: Rapid prototyping, testing new model architectures, or low-traffic internal tools where ease of deployment outweighs raw throughput.
While TensorRT-LLM is optimized for maximum speed, vLLM provides a robust and flexible baseline .
- High throughput through dynamic batching and efficient memory utilization
- Paged KV cache management for handling long contexts and concurrent requests
- Strong support for open-source model ecosystems
- Rapid Adoption: It allows us to onboard new model architectures immediately without waiting for a custom TensorRT build.
- Benchmarking Insight: In our internal tests, vLLM provided a strong baseline but often lacked the specific max-token optimizations present in our custom TRT engines . We use it strategically for initial testing before committing to a full TensorRT optimization pipeline.
Conclusion
Large language model inference introduces a fundamentally new class of infrastructure challenges—where performance is governed not just by raw compute, but by memory efficiency, intelligent scheduling, runtime specialization, and lifecycle automation. Unlike traditional ML serving, LLM inference requires systems that understand token-level execution, manage rapidly growing context state, and continuously balance latency, throughput, and cost under highly dynamic workloads.
The LLM Inference Framework addresses these challenges by transforming inference into a fully automated, reproducible lifecycle—from model onboarding and compilation to deployment, optimization, and observability. By integrating automated quantization and engine compilation, intelligent runtime selection, cold-start mitigation strategies, and LLM-specific observability metrics such as Time-to-First-Token and Inter-Token Latency, the platform ensures both high performance and operational simplicity.
Equally important, the framework is designed with flexibility and future evolution in mind. Its runtime-agnostic architecture enables seamless adoption of emerging inference engines, hardware accelerators, and optimization techniques without requiring platform redesign. This ensures that teams can continuously leverage advancements in the rapidly evolving LLM ecosystem while maintaining consistent operational workflows.
Ultimately, the goal of the platform is to make production-scale LLM deployment as seamless and reliable as traditional software deployment—allowing teams to focus on building intelligent applications rather than managing infrastructure complexity. By combining lifecycle automation, runtime optimization, and deep observability, the LLM Inference Framework provides a scalable foundation for delivering fast, cost-efficient, and production-ready LLM experiences.
Future Explorations
While we have achieved significant milestones in latency and throughput, the landscape of GenAI is evolving rapidly. Our roadmap focuses on increasing flexibility, reducing costs, and enhancing reliability for enterprise-grade workloads. Here is what we are building next:
- TPU Support: To diversify our hardware supply chain and further optimize cost-per-token, we are evaluating Google Cloud TPUs to bake it into our platform. By leveraging the JAX and PyTorch/XLA ecosystems, we aim to unlock the massive throughput potential of TPU v5e chips, particularly for our open-source Llama models. This will allow the hardware profiler to dynamically choose between NVIDIA GPUs and Google TPUs based on real-time availability and price-performance metrics.
- Multi-LoRA Serving (Serverless Experience): Currently, deploying a fine-tuned model requires a dedicated GPU. We are building support for Multi-LoRA serving, which will allow us to serve hundreds of unique, fine-tuned adapters on top of a single frozen base model. This will drastically reduce costs for multi-tenant applications, enabling a "serverless" experience where specific fine-tunes are hot-swapped instantly per request.
- Spot Instance Orchestration: To further optimize cloud costs, we are developing fault-tolerant mechanisms to run inference workloads on Spot Instances. By implementing aggressive checkpointing and seamless request draining, we aim to leverage cheaper, preemptible compute capacity without interrupting the user's streaming experience.
- Semantic Caching Layer: We plan to move beyond standard Prefix Caching to implement Semantic Caching. By using a vector database to fetch responses for semantically similar queries (e.g., "How do I reset my password?" vs. "Password reset steps"), we can bypass the GPU entirely for repetitive queries, reducing latency to near-zero.
- Context-Aware Autoscaling: Standard CPU/GPU utilization metrics are often insufficient signals for scaling LLMs. We are working on KV-cache pressure metrics for autoscaling. This ensures that we scale out before the memory fills up, preventing eviction-based slowdowns during traffic spikes.
- Online Evaluation & Guardrails: We are integrating a lightweight "Trust Layer" into the proxy. This will allow for low-latency input/output filtering (Guardrails) and asynchronous "LLM-as-a-Judge" evaluation pipelines to monitor response quality in production, not just system health.