BharatMLStack - Predator
Predator is a scalable, high-performance model inference service built as a wrapper around the NVIDIA Triton Inference Server. It is designed to serve a variety of machine learning models (Deep Learning, Tree-based, etc.) with low latency in a Kubernetes (K8s) environment.
The system integrates seamlessly with the Online Feature Store (OnFS) for real-time feature retrieval and uses Horizon as the deployment orchestration layer. Deployments follow a GitOps pipeline — Horizon generates Helm configurations, commits them to GitHub, and Argo Sync reconciles the desired state onto Kubernetes.
High-Level Design
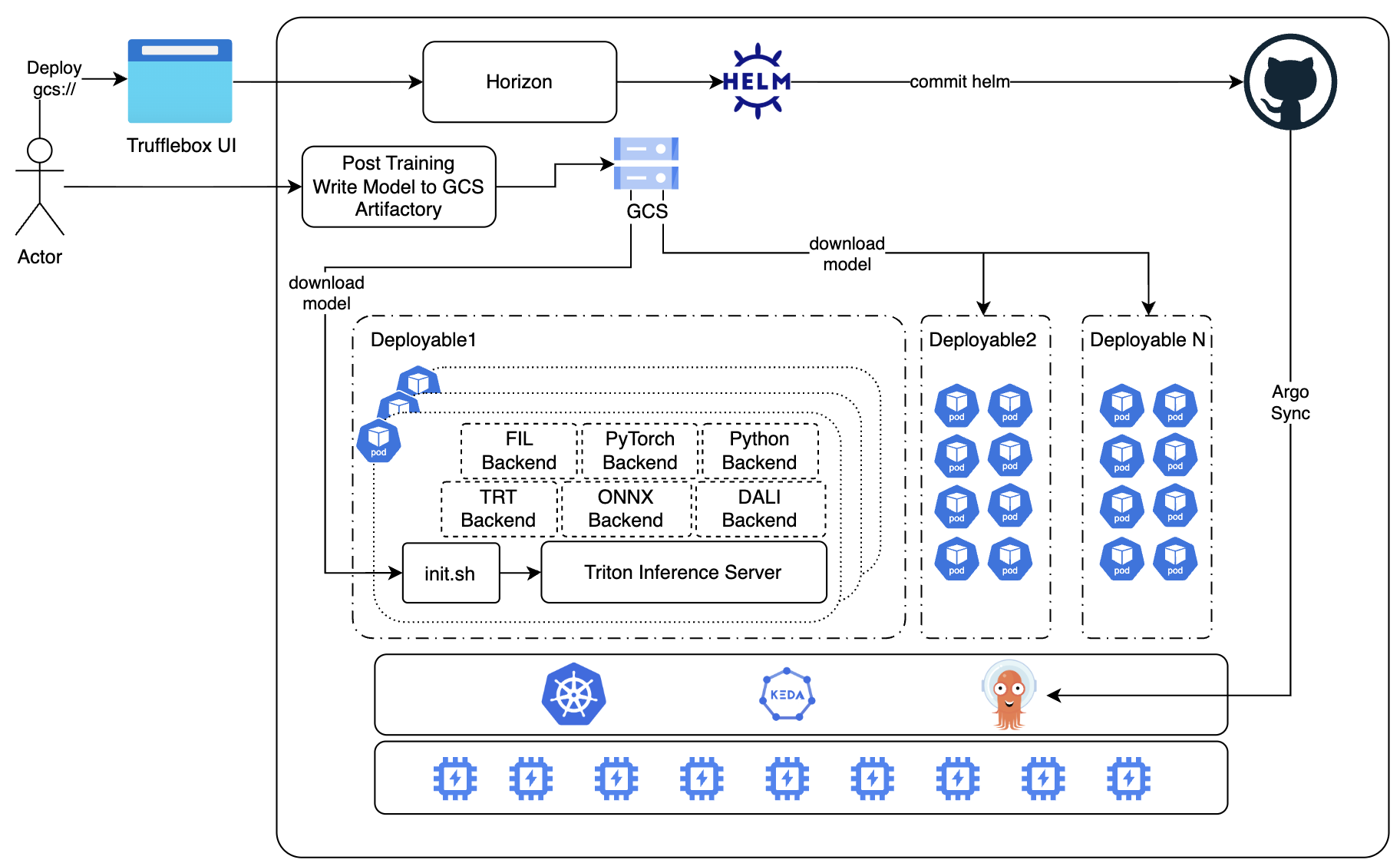
End-to-End Flow
-
Model Deployment Trigger: An actor initiates deployment through Trufflebox UI, specifying the GCS path (
gcs://) of the trained model. Separately, post-training pipelines write model artifacts to GCS Artifactory. -
Orchestration via Horizon: Trufflebox UI communicates with Horizon, the deployment orchestration layer. Horizon generates the appropriate Helm chart configuration for the inference service.
-
GitOps Pipeline: Horizon commits the Helm values to a GitHub repository. Argo Sync watches the repo and reconciles the desired state onto the Kubernetes cluster, creating or updating deployable units.
-
Deployable Units (Deployable 1 … N): Each deployable is an independent Kubernetes deployment that:
- Downloads model artifacts from GCS at startup via an
init.shscript. - Launches a Triton Inference Server instance loaded with the model.
- Runs one or more pods, each containing the inference runtime and configured backends.
- Downloads model artifacts from GCS at startup via an
-
Triton Backends: Each Triton instance supports pluggable backends based on the model type:
- FIL — GPU-accelerated tree-based models (XGBoost, LightGBM, Random Forest).
- PyTorch — Native PyTorch models via LibTorch.
- Python — Custom preprocessing/postprocessing or unsupported model formats.
- TRT (TensorRT) — GPU-optimized serialized TensorRT engines.
- ONNX — Framework-agnostic execution via ONNX Runtime.
- DALI — GPU-accelerated data preprocessing (image, audio, video).
-
Autoscaling with KEDA: The cluster uses KEDA (Kubernetes Event-Driven Autoscaling) to scale deployable pods based on custom metrics (CPU utilization, GPU utilization via DCGM, queue depth, etc.). The underlying Kubernetes scheduler places pods across GPU/CPU node pools.
Key Design Principles
- GitOps-driven: All deployment state is version-controlled in Git; Argo Sync ensures cluster state matches the declared configuration.
- Isolation per deployable: Each model or model group gets its own deployable unit, preventing noisy-neighbor interference.
- Init-based model loading: Models are materialized to local disk before Triton starts, ensuring deterministic startup and no runtime dependency on remote storage.
- Pluggable backends: The same infrastructure serves deep learning, tree-based, and custom models through Triton's backend abstraction.
Inference Engine: Triton Inference Server
NVIDIA Triton Inference Server is a high-performance model serving system designed to deploy ML and deep learning models at scale across CPUs and GPUs. It provides a unified inference runtime that supports multiple frameworks, optimized execution, and production-grade scheduling.
Triton operates as a standalone server that loads models from a model repository and exposes standardized HTTP/gRPC APIs. Predator uses gRPC for efficient request and response handling via the helix client.
Core Components
- Model Repository: Central directory where models are stored. Predator typically materializes the model repository onto local disk via an init container, enabling fast model loading and eliminating runtime dependency on remote storage during inference.
Backends
A backend is the runtime responsible for executing a model. Each model specifies which backend runs it via configuration.
| Backend | Description |
|---|---|
| TensorRT | GPU-optimized; executes serialized TensorRT engines (kernel fusion, FP16/INT8). |
| PyTorch | Serves native PyTorch models via LibTorch. |
| ONNX Runtime | Framework-agnostic ONNX execution with TensorRT and other accelerators. |
| TensorFlow | Runs TensorFlow SavedModel format. |
| Python backend | Custom Python code for preprocessing, postprocessing, or unsupported models. |
| Custom backends | C++/Python backends for specialized or proprietary runtimes. |
| DALI | GPU-accelerated data preprocessing (image, audio, video). |
| FIL (Forest Inference Library) | GPU-accelerated tree-based models (XGBoost, LightGBM, Random Forest). |
Key Features
- Dynamic batching: Combines multiple requests into a single batch at runtime — higher GPU utilization, improved throughput, reduced latency variance.
- Concurrent model execution: Run multiple models or multiple instances of the same model; distribute load across GPUs.
- Model versioning: Support multiple versions per model.
- Ensemble models: Pipeline of models as an ensemble; eliminates intermediate network hops, reduces latency.
- Model instance scaling: Multiple copies of a model for parallel inference and load isolation.
- Observability: Prometheus metrics, granular latency, throughput, GPU utilization.
- Warmup requests: Preload kernels and avoid cold-start latency.
Model Repository Structure
model_repository/
├── model_A/
│ ├── config.pbtxt
│ ├── 1/
│ │ └── model.plan
│ ├── 2/
│ │ └── model.plan
├── model_B/
│ ├── config.pbtxt
│ ├── 1/
│ └── model.py
The config.pbtxt file defines how Triton loads and executes a model: input/output tensors, batch settings, hardware execution, backend runtime, and optimization parameters. At minimum it defines: backend/platform, max_batch_size, inputs, outputs.
Sample config.pbtxt
name: "product_ranking_model"
platform: "tensorrt_plan"
max_batch_size: 64
input [ { name: "input_embeddings" data_type: TYPE_FP16 dims: [ 128 ] }, { name: "context_features" data_type: TYPE_FP32 dims: [ 32 ] } ]
output [ { name: "scores" data_type: TYPE_FP32 dims: [ 1 ] } ]
instance_group [ { kind: KIND_GPU count: 2 gpus: [0] } ]
dynamic_batching { preferred_batch_size: [8,16,32,64] max_queue_delay_microseconds: 2000 }
Kubernetes Deployment Architecture
Predator inference services are deployed on Kubernetes using Helm-based deployments for standardized, scalable, GPU-optimized model serving. Each deployment consists of Triton Inference Server wrapped within a Predator runtime, with autoscaling driven by CPU and GPU utilization.
Pod Architecture
Predator Pod
├── Init Container (Model Sync)
├── Triton Inference Server Container
Model artifacts and runtime are initialized before inference traffic is accepted.
Init Container
- Download model artifacts from cloud storage (GCS).
- Populate the Triton model repository directory.
- Example:
gcloud storage cp -r gs://.../model-path/* /models
Benefits: deterministic startup (Triton starts only after models are available), separation of concerns (image = runtime, repository = data).
Triton Inference Server Container
- Load model artifacts from local repository.
- Manage inference scheduling, request/response handling, and expose inference endpoints.
Triton Server Image Strategy
The Helm chart uses the Triton container image from the internal artifact registry. Production uses custom-built images (only required backends, e.g. TensorRT, Python) to reduce size and startup time. Unnecessary components are excluded; images are built internally and pushed to the registry.
Response Caching: Custom cache plugins can be added at image build time for optional inference response caching — reducing redundant execution and GPU use for repeated inputs.
Image Distribution Optimization
- Secondary boot disk image caching: Images are pre-cached on GPU node pool secondary boot disks to avoid repeated pulls during scale-up and reduce pod startup time and cold-start latency.
- Image streaming: Can be used to progressively pull layers for faster time-to-readiness during scaling.
Health Probes
Readiness and liveness use /v2/health/ready. Triton receives traffic only after model loading; failed instances are restarted automatically.
Resource Configuration
Sample GPU resource config:
limits:
cpu: 7000m
memory: 28Gi
gpu: 1
Autoscaling Architecture
Predator uses KEDA (Kubernetes Event-Driven Autoscaling) for scaling deployable pods. KEDA supports custom metric sources including:
- CPU / Memory utilization for CPU-based deployments.
- GPU utilization via DCGM (Data Center GPU Manager) for GPU pods — covering utilization, memory, power, etc.
- Custom Prometheus queries for application-level scaling signals (e.g., inference queue depth, request latency).
KEDA ScaledObjects are configured per deployable, enabling fine-grained, independent scaling for each model or model group.
Contributing
We welcome contributions! See the Contributing Guide.
Community & Support
- Discord: community chat
- Issues: GitHub Issues
- Email: ml-oss@meesho.com
License
BharatMLStack is open-source under the BharatMLStack Business Source License 1.1.